Full Case Study – Emails
Setting up a new .qmd file
For this case study, we will do what I expect you to do for the final project.
We will start by creating a new .qmd file.
- Click on the
Fileoption on the top menu, chooseNew Filethen click onQuarto Document... - Fill out title and author and click on
Create
The Data
Download the email data and set it up in your project.
In your .qmd file, add a code chunk for the follow (shortcut: option + command + i for macs, crtl + alt + i for windows)
You can check the data dictionary to understand what the variables are.
Question
What factors have an effect on whether an email message is spam or not?
Descriptive statistics
What percentage of the data is spam?
Descriptive statistics
What percentage of emails sent to multiple recipients spam?
| to_multiple | mean(spam) |
|---|---|
| 0 | 0.1075432 |
| 1 | 0.0193548 |
What other variables can we investigate?
Plots
What is the distribution of number of characters of spam vs. non-spam messages?
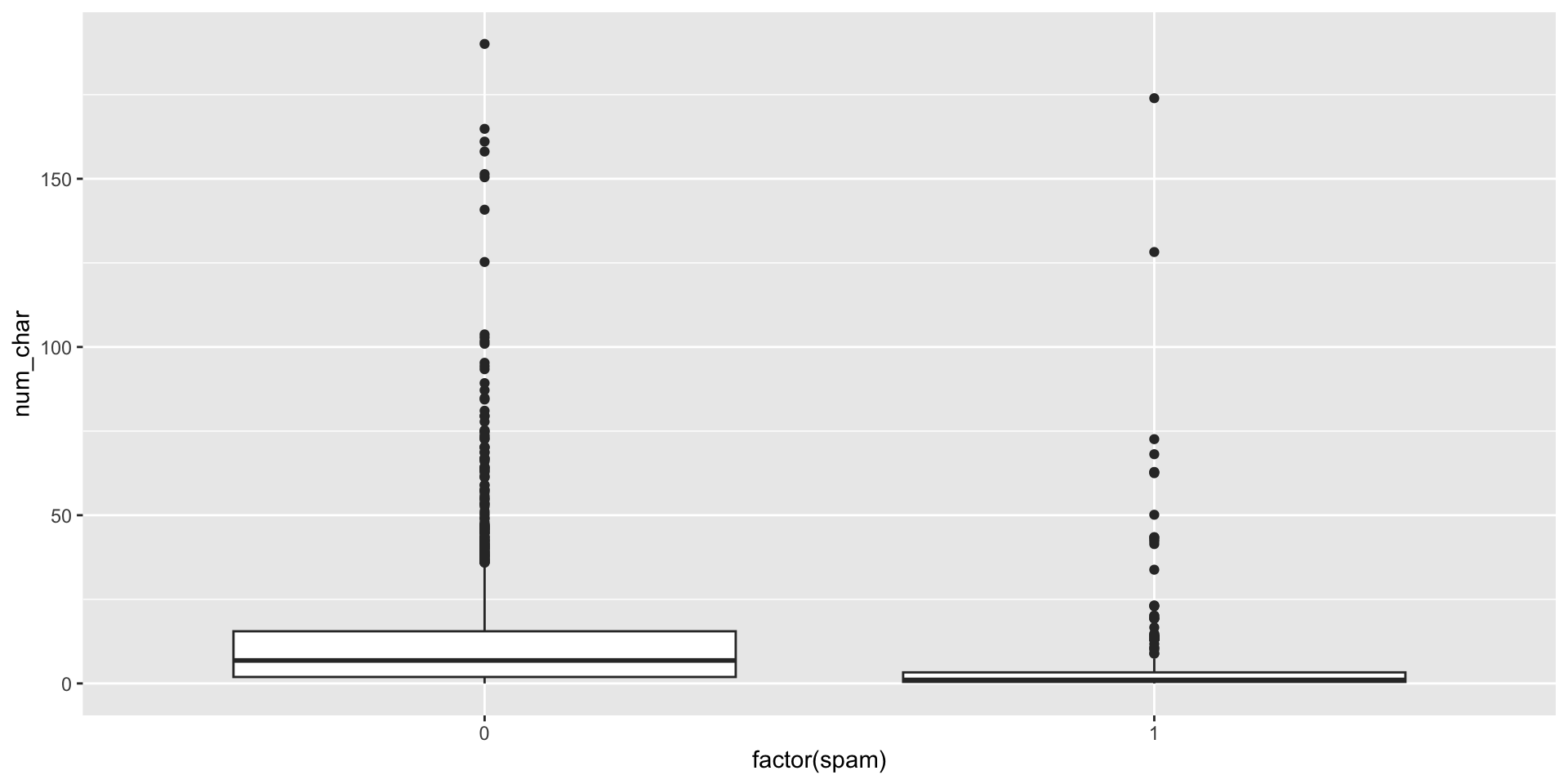
What other plots can we create?
In-class activity
Go to gradescope and answer today’s in-class activity about plots
Model
What factors have an effect on whether an email message is spam or not?
model <- glm(spam ~ to_multiple + attach + num_char + number,
data = email,
family = binomial)
anova(model)| Df | Deviance | Resid. Df | Resid. Dev | Pr(>Chi) | |
|---|---|---|---|---|---|
| NULL | NA | NA | 3920 | 2437.180 | NA |
| to_multiple | 1 | 65.16041 | 3919 | 2372.019 | 0.0000000 |
| attach | 1 | 8.82110 | 3918 | 2363.198 | 0.0029777 |
| num_char | 1 | 98.71806 | 3917 | 2264.480 | 0.0000000 |
| number | 2 | 123.19374 | 3915 | 2141.286 | 0.0000000 |
Model
Variance explained
Find a good model.
Interpret Results
You can check the effects of each variable.
Results
- Write up your results and render your document.
- You will see that you now have .html files in your list of files.
- Include the .html files for your final project submission