Exploring Categorical Data
Distribution – adding categorical variable
Histogram: the frequency distribution of a continuous variable across different groups
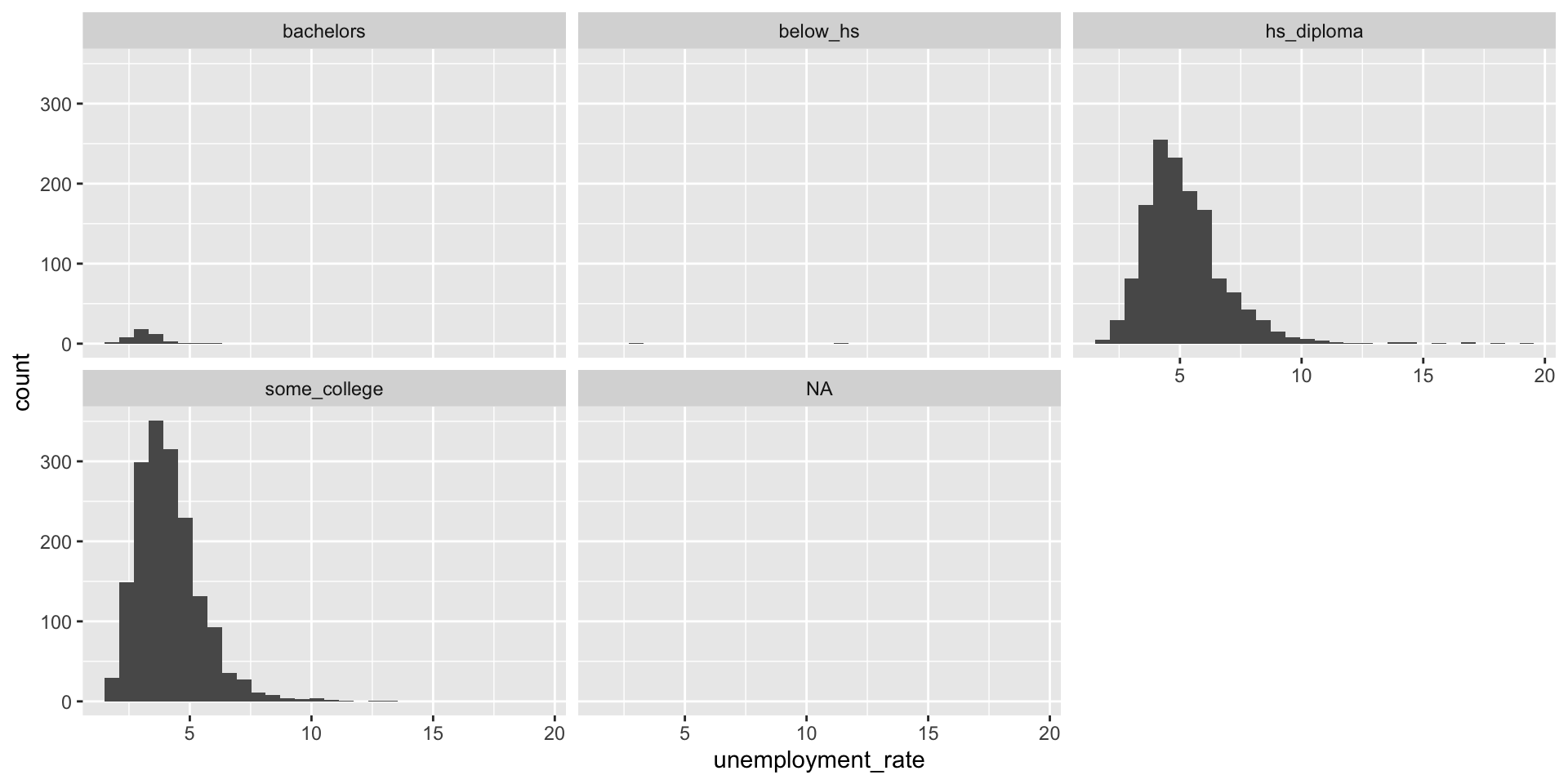
Distribution – with filtered data
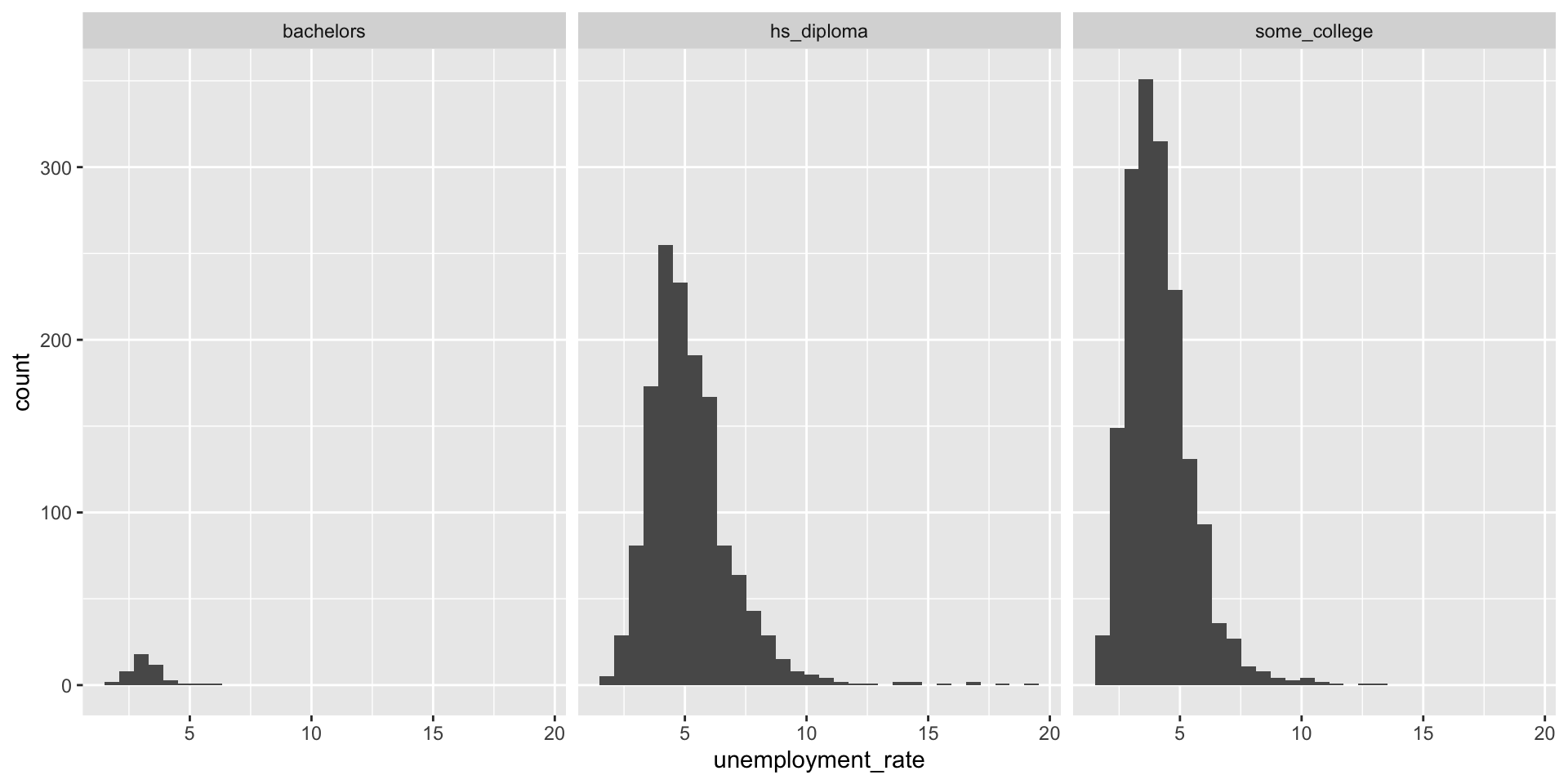
Variability – Box plot (IQR)
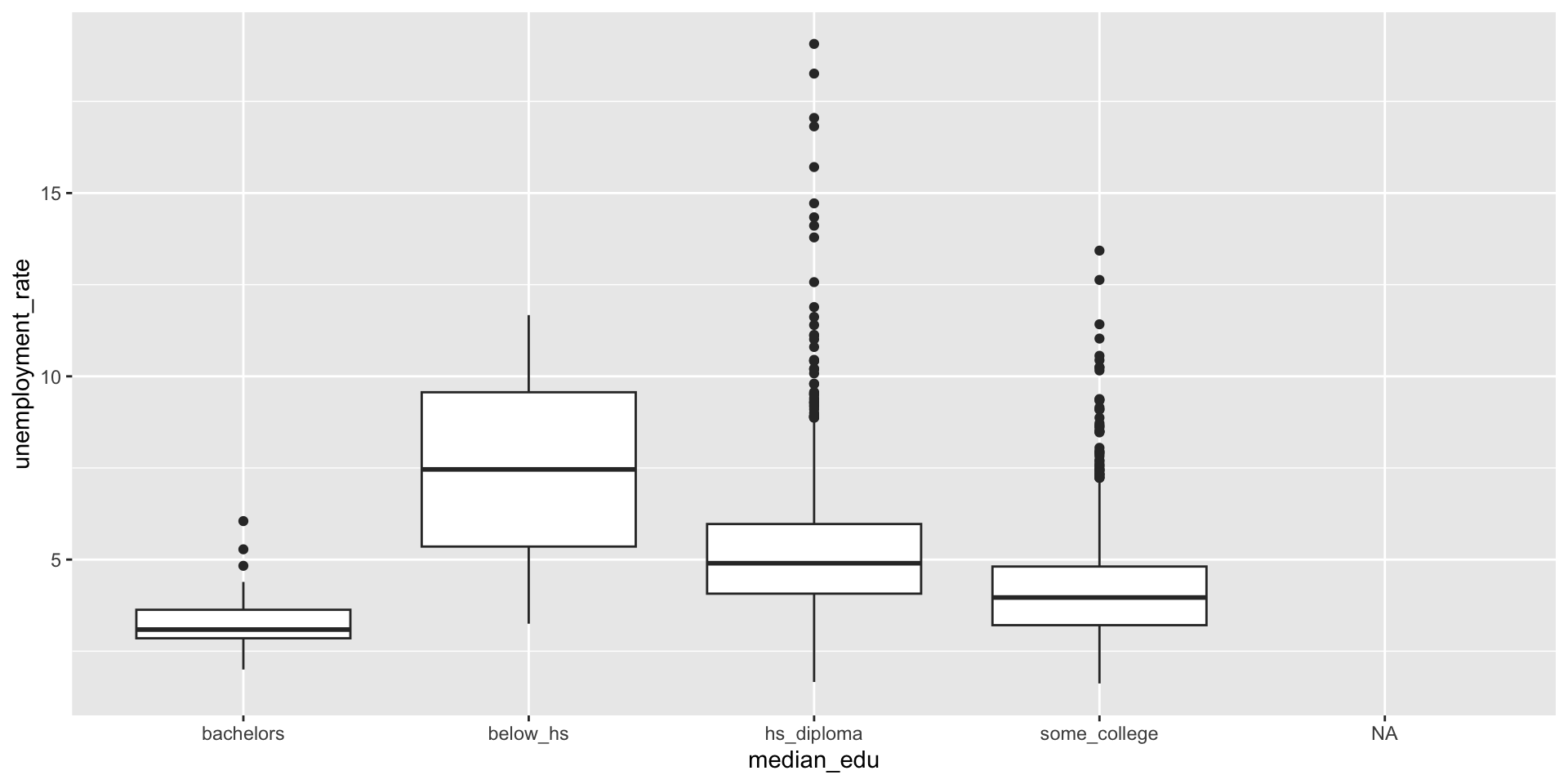
Histogram: the frequency distribution of a continuous variable across different groups