Clustering
Recap: Supervised vs. Unsupervised Learning
- Supervised Learning
- Data: both the features, x, and a target, y, for each item in the dataset
- Goal: ‘learn’ how to predict the target from the features, y = f(x)
- Example: Regression and Classification
Recap: Supervised vs. Unsupervised Learning
- Unsupervised Learning
- Data: Only the features, x, for each item in the dataset
- Goal: discover ‘interesting’ things about the dataset
- Example: Clustering, Dimensionality reduction, Principal Component Analysis (PCA)
Clustering
- Clustering is the task of discovering unknown subgroups in data, or clusters
- The goal is to partition the dataset into clusters where ‘similar’ items are in the same cluster and ‘dissimilar’ items are in different clusters
- Example:
- Social Network Analysis: Clustering can be used to find communities
- Handwritten digits where the digits are unknown
Clustering
- Partition data into groups (clusters)
- Points within a cluster should be “similar”
- Points in different cluster should be “different”
Goal of Clustering
- Data Exploration
- Are there coherent groups ?
- How many groups are there ?
- Data Partitioning
- Divide data by group before further processing
Formulation of K-means Clustering Method
- Data: A collection of points \(x_i\), for i = 1,…,n
- Find k centers, assign each point x to a cluster as to minimize the total intra-cluster distance
- The total intra-cluster distance is the total squared Euclidean distance from each point to the center of its cluster
- It’s a measure of the variance or internal coherence of the cluster
K-Means Algorithm
- Pick number of clusters k
- Pick k random points as “cluster center” (or centroid)
- While cluster centers change:
- Assign each data point to its closest cluster center
- Recompute cluster centers as the mean of the assigned points
K-Means Algorithm
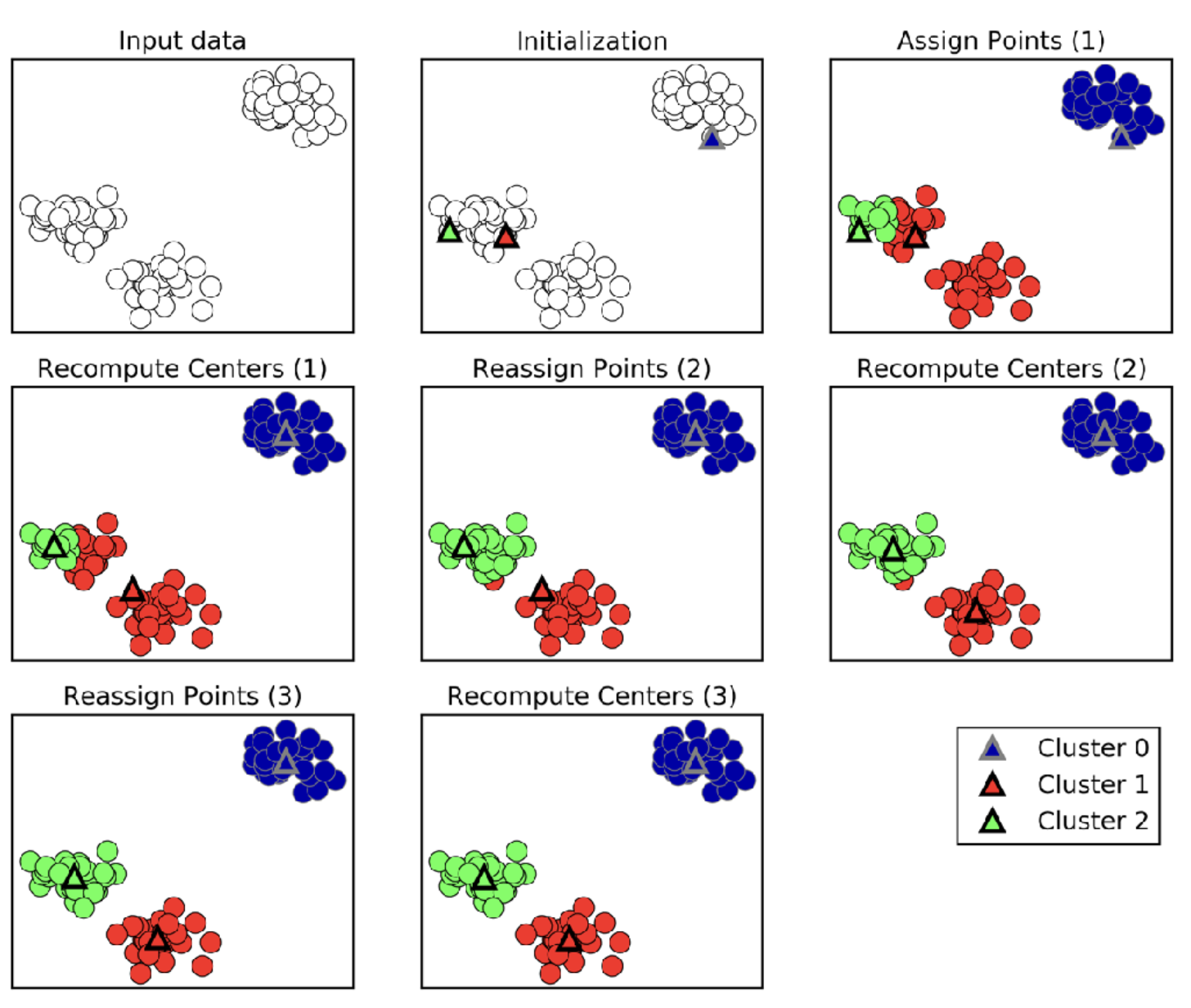
K-Means Algorithm
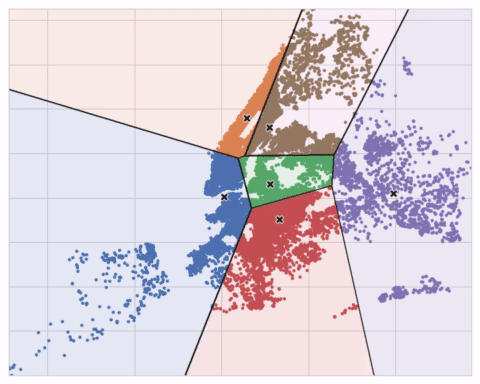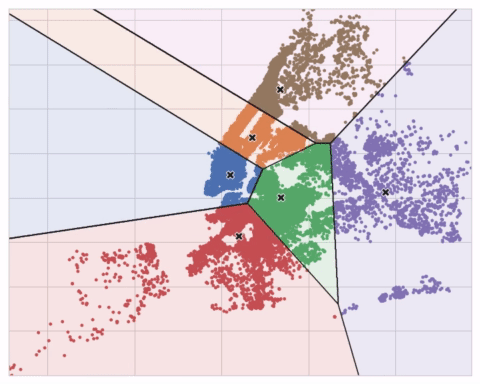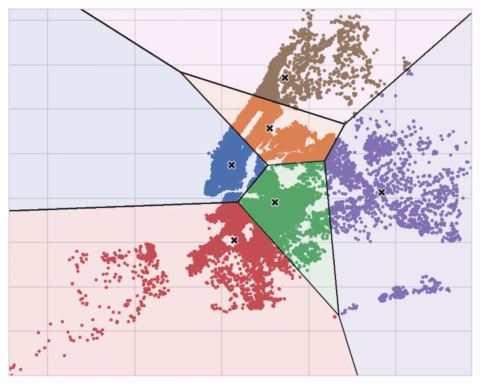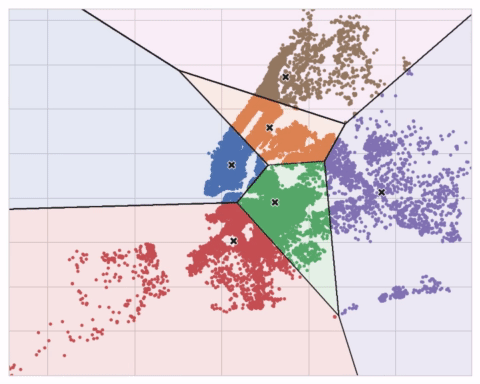
The K-means clustering algorithm on Airbnb rentals in NYC.
Limitations of K-Means
- Restriction to cluster shapes
- Restriction to distance of points to centers
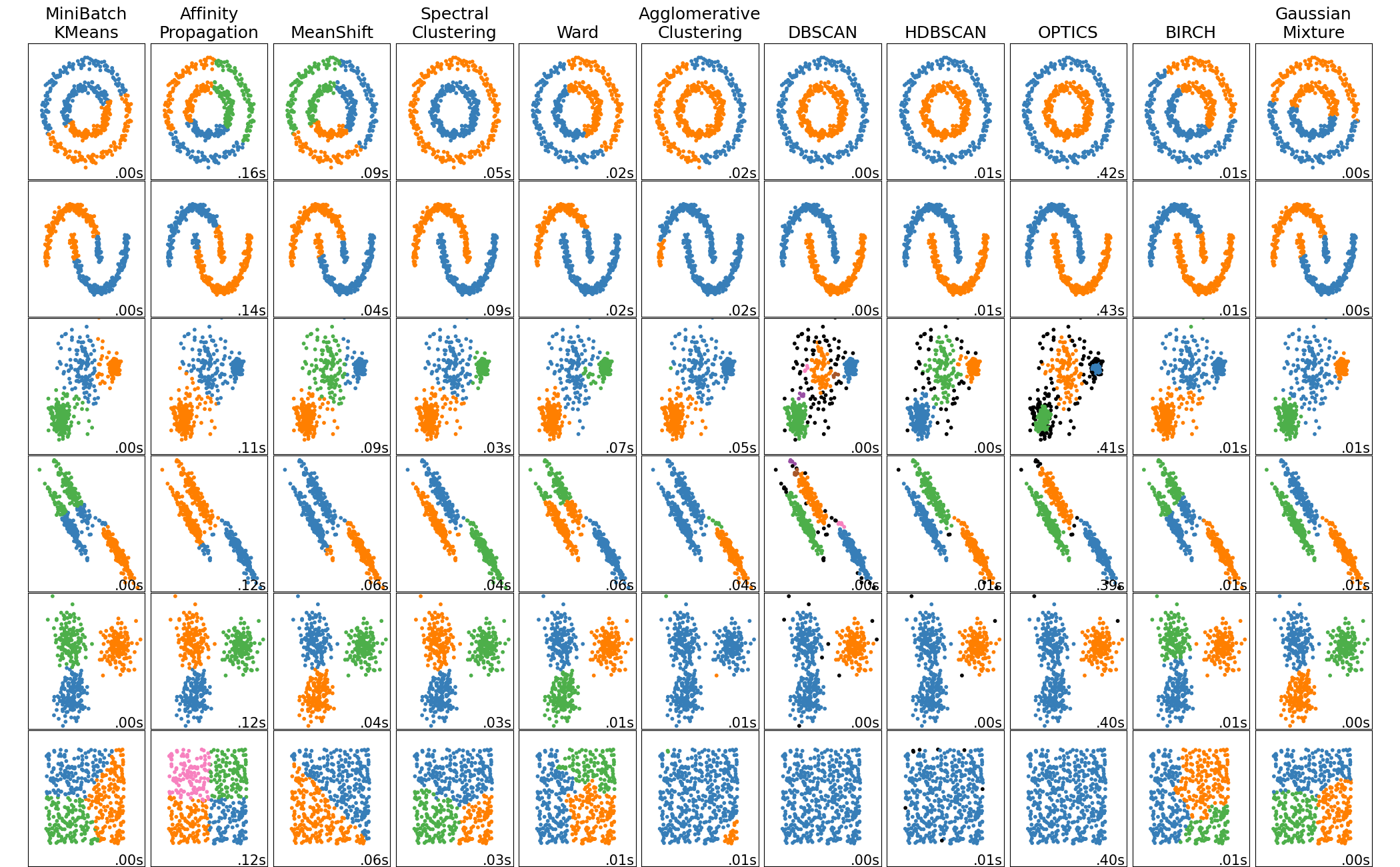
Overview of clustering methods
Dimensionality Reduction
- It is often beneficial to reduce number of dimensions before running K-means
- Simplification of the data – it makes it easier to find clusters
Curse of Dimensionality
As the number of dimensions (features) in a dataset increases, the chances of two data points being close to each other become increasingly rare