Data
Data
The data we will be working with contains variables as columns and observations as rows (often called tidy data)
Feature engineering: data –> features
Remember the spam vs not spam example? How do we go from words to features?
Data quality
What to look for:
- a data dictionary
- information on how the data were collected
Data format
- tabular – tables, rows and columns
- hierachical – values are nested (like a tree)
- unstructured data – no structure, for example: emails, videos, pictures
Tabular Data
Rows and Columns
| Day | High | Low | Wind | Forecast |
|---|---|---|---|---|
| Tuesday | 24 | 15 | 0 to 15 mph | Sunny |
| Wednesday | 38 | 17 | 5 to 15 mph | Mostly Sunny |
| Thursday | 34 | 13 | 5 to 15 mph | Mostly Sunny |
Hierachical Data
Tuesday:
↳ Temperature:
↳ Low: 15
↳ High: 24
↳ Wind:
↳ Speed: 0 to 15 mph
↳ Direction: West
Wednesday:
↳ Temperature:
↳ Low: 17
↳ High: 38
↳ Wind:
↳ Speed: 5 to 15 mph
↳ Direction: North WestUnstructured Data
One winter, I became very quiet
and saw my life. It was February
and outside in the city streets,
snow fell but would not collect.
I bought snapdragons and thistle,
got some discount peach roses
that smelled off. I split them
between vases and moved
the bouquets from room to room
while a violin solo rang out.Matrices and Vectors
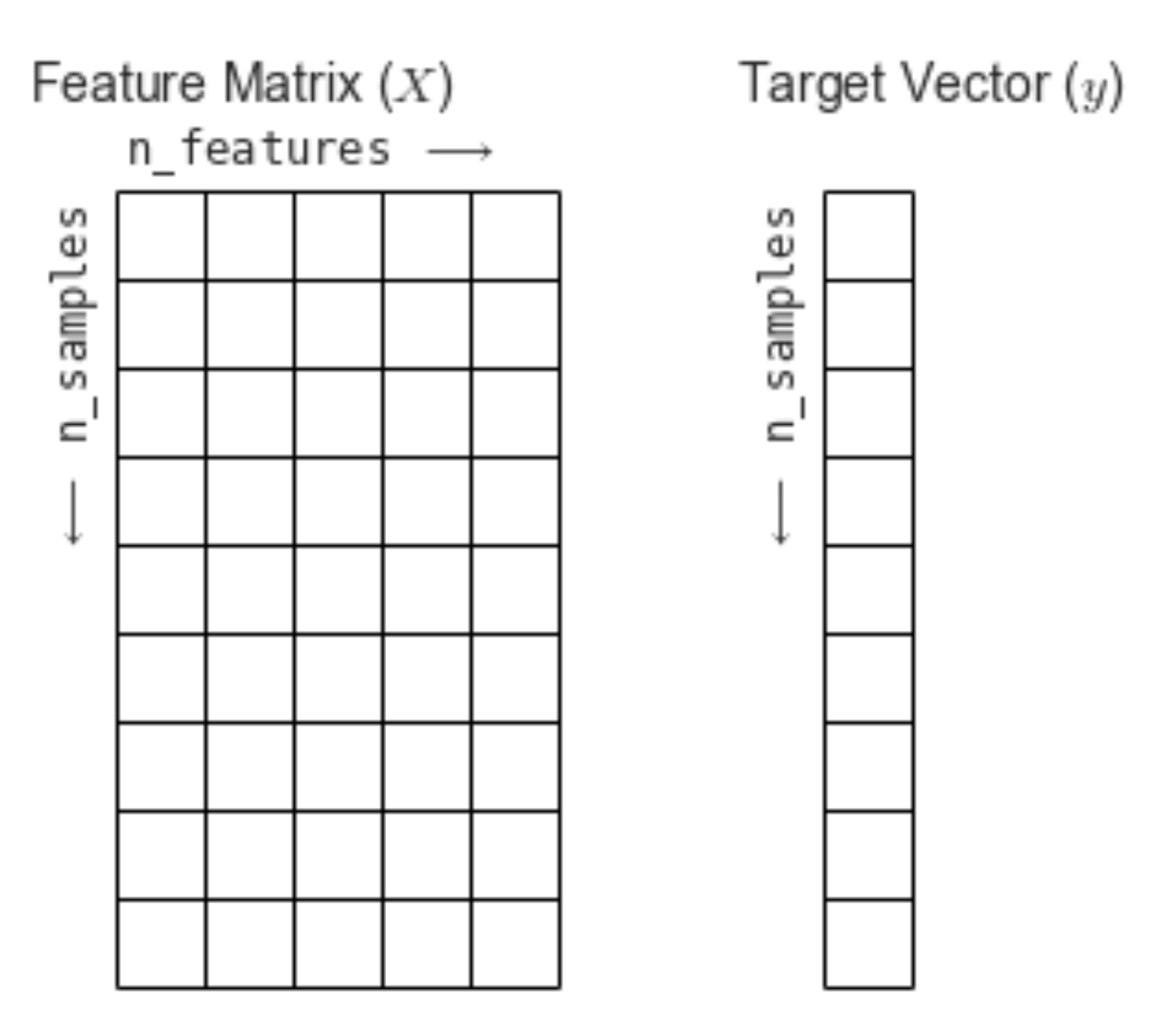
For machine learning, we have a feature matrix that contains all of our predictor variables, and a target vector that contains the label or target for each observation.
Training, Validation and Testing
We usually need enough data to split it into training and validation (and testing)
- Most of our data will be used to build our model (training)
- We never predict data that was in our training data set
- Our validation data set is used to fine tune our model (we can also do cross-validation)
- The test data set is used to assess the final mode that has been selected during the validation process
The goal is to not overfit our data to our model
Practice
- Access this kaggle dataset on house prices
- What are the variables in the data? (is there a data dictionary?)
- What is this data set from? What’s its source?
- Any problems you see with it?
- Which variable could we use as target (response)?
- Which variables would you use as features? Any feature engineering you can think of?